NVIDIA H100 and GH200 Selection Guide: Hardware Adaptation Solutions for AI and HPC Loads

As AI models continue to grow in scale, inference throughput requirements increase, and data processing becomes increasingly complex, the choice of computing hardware is no longer simply a matter of “computing power.” Graphics memory capacity, memory bandwidth, the collaborative efficiency of CPU and GPU, and system-level architecture design are becoming key factors determining the performance ceiling of AI and HPC workloads.
Within the NVIDIA Hopper architecture, the H100 Tensor Core GPU and the GH200 Grace Hopper Superchip are two highly representative platforms.
● H100 : A high-performance data center GPU for general AI training and inference.
● GH200 : Deeply integrates the H100 with the Grace CPU, targeting scenarios with limited memory and system architecture.

This article will provide a systematic comparison of the H100 and GH200 from multiple dimensions, including architectural evolution, system design, performance characteristics, and typical application scenarios , to help you make a more rational choice based on your actual workload.
I. Core Overview of H100 and GH200
1. NVIDIA H100(Hopper GPU)
The H100 is a data center GPU designed by NVIDIA specifically for large-scale AI and HPC workloads. Its core highlights are the introduction of fourth-generation Tensor Cores and the Transformer Engine that supports FP8 precision, enabling Transformer-based models to achieve breakthroughs in both throughput and efficiency.
Core features include:
● Built on the Hopper architecture and manufactured using a 5nm process;
● Equipped with 80GB HBM3 high-speed memory, providing ultra-high memory bandwidth;
● Supports fourth-generation NVLink, enabling efficient multi-GPU expansion;
● Offers both PCIe and SXM form factors to adapt to different deployment needs;
As a general-purpose accelerator, it can efficiently handle various training and inference workloads.

2. NVIDIA GH200 (Grace Hopper Super Chip)
The GH200 is not a standalone GPU product, but rather a system-level solution—tightly coupling the H100 GPU with the NVIDIA Grace CPU via NVLink-C2C interconnect technology. Its core innovation is a unified memory architecture, allowing the CPU and GPU to share a large, consistent memory pool, completely changing the traditional logic of separate memory usage.
Core features include:
● Single-package integration of Grace CPU and H100 GPU, requiring no additional adaptation;
● The shared memory pool capacity can be expanded to hundreds of GB to meet ultra-large memory requirements;
● It features high-bandwidth, low-latency CPU-GPU interconnect capabilities, resulting in outstanding collaborative efficiency;
● Designed specifically for memory-intensive workloads and workloads requiring deep CPU-GPU collaboration;
The core advantage lies in solving the performance bottlenecks caused by system architecture and data movement, rather than simply improving GPU computing power.

II. Architectural Evolution: From GPU Centralization to System-Level Collaboration
Although the H100 and GH200 belong to the same Hopper architecture, they represent different levels of system design thinking, with the core differences lying in the optimization direction and application scope.
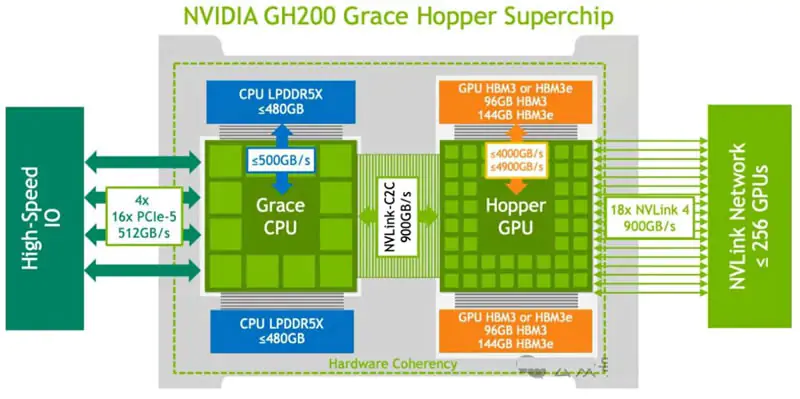
1. NVIDIA H100: Ultimate Optimization of GPU Computing Power
The core design of the H100 is to enhance the acceleration capabilities of GPU-centralized systems, and it incorporates multiple architectural innovations to address modern AI and HPC workloads:
● The combination of the fourth-generation Tensor Core and Transformer Engine supports FP8 accuracy, significantly improving training and inference speed while ensuring model accuracy.
● Added DPX instruction set, specifically designed to accelerate dynamic planning workloads and expand adaptability scenarios;
● Distributed shared memory and thread block clustering technology improve the execution efficiency of streaming multiprocessors (SM);
● The second-generation multi-instance GPU (MIG) architecture increases the computing power and memory quota of each instance and optimizes the multi-load isolation effect;
● Supports confidential computing, providing a secure execution environment for sensitive scenarios such as finance and government affairs.
These features make the H100 a highly targeted, dedicated accelerator capable of efficiently handling various computationally intensive tasks.
2. NVIDIA GH200: A Revolutionary Architecture for CPU-GPU Collaboration
The core breakthrough of the GH200 lies in expanding the optimization scope from a single GPU to the entire system, redefining the collaboration mode between the CPU and GPU:
● It abandons the traditional PCIe interface and adopts NVLink-C2C interconnect technology to achieve seamless coupling between the CPU and GPU;
● Build a unified memory architecture so that CPU and GPU memory can access each other without explicit copying, simplifying memory management and reducing latency;
● It solves the data movement bottleneck of “CPU preprocessing → GPU computing → CPU postprocessing” in the traditional architecture, improving end-to-end efficiency;
● The optimization focuses on data flow efficiency rather than simply improving single-point computing performance, and is designed for complex workloads that require deep collaboration between CPU and GPU.
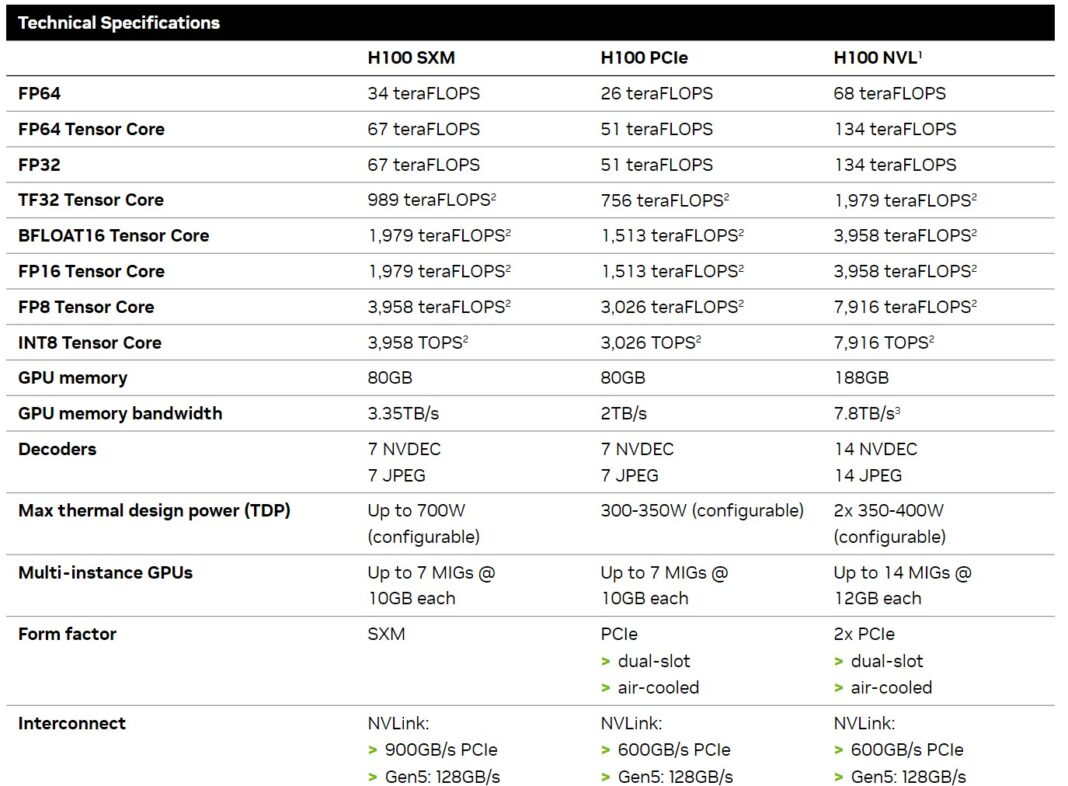
III. Core Specifications: System-level Comparison
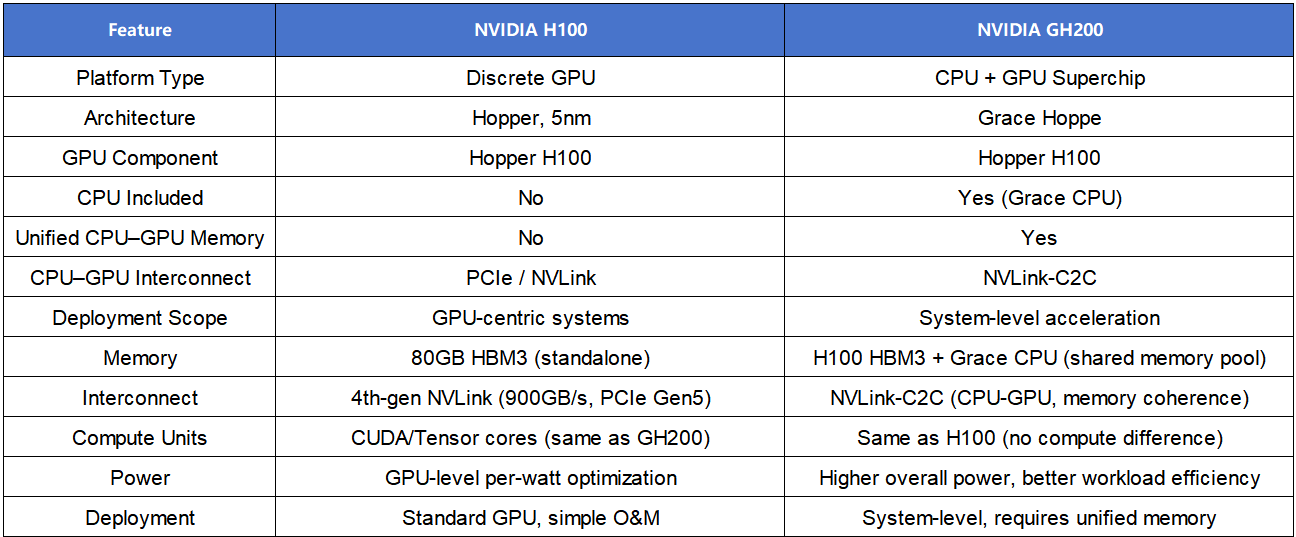
Note: The core computing capabilities of the two products are exactly the same. The performance difference mainly stems from the memory architecture, interconnect design, and system coordination efficiency, rather than the hardware specifications of the GPU itself.
IV. Performance: Adaptability differences under different loads
The H100 and GH200 are based on the same Hopper GPU. The actual performance difference does not come from raw computing power, but rather from memory architecture, interconnect design and system-level efficiency.
1. Computational performance comparison
● The two products have similar single-GPU performance and minimal difference in throughput;
● The performance advantages all come from the underlying optimizations of the Hopper architecture, including the high-efficiency computing power of Tensor Cores and support for FP8 precision;
● In this scenario, the H100 offers a better cost-performance ratio, is simple to deploy and maintain, and is compatible with existing GPU cluster infrastructure.
2. Differences in memory architecture and bandwidth
● The H100 uses separate memory for the CPU and GPU, connected via PCIe or NVLink. Although the bandwidth is high, data still needs to be explicitly copied when moving between the CPU and GPU.
● The GH200 enables direct and consistent access to CPU and GPU memory, builds a large-capacity shared memory pool, significantly reduces data movement overhead, and simplifies memory management.
For workloads with high memory consumption, frequent CPU-GPU synchronization, or complex data pipelines, the GH200 can significantly reduce latency and improve effective throughput.
3. Interconnectivity and scalability
In large-scale deployment scenarios, the impact of interconnect design is particularly prominent:
● The H100 supports NVLink to achieve high-bandwidth communication between GPUs, making it suitable for multi-GPU training and distributed inference;
● The GH200 extends high-bandwidth interconnect to CPU-GPU communication via NVLink-C2C, enabling tighter coupling between compute-intensive and memory-intensive operations.
This architectural difference becomes even more apparent when the system is scaled up to multiple GPUs or nodes—in communication-intensive workloads, the GH200 can reduce synchronization overhead and break through performance bottlenecks.
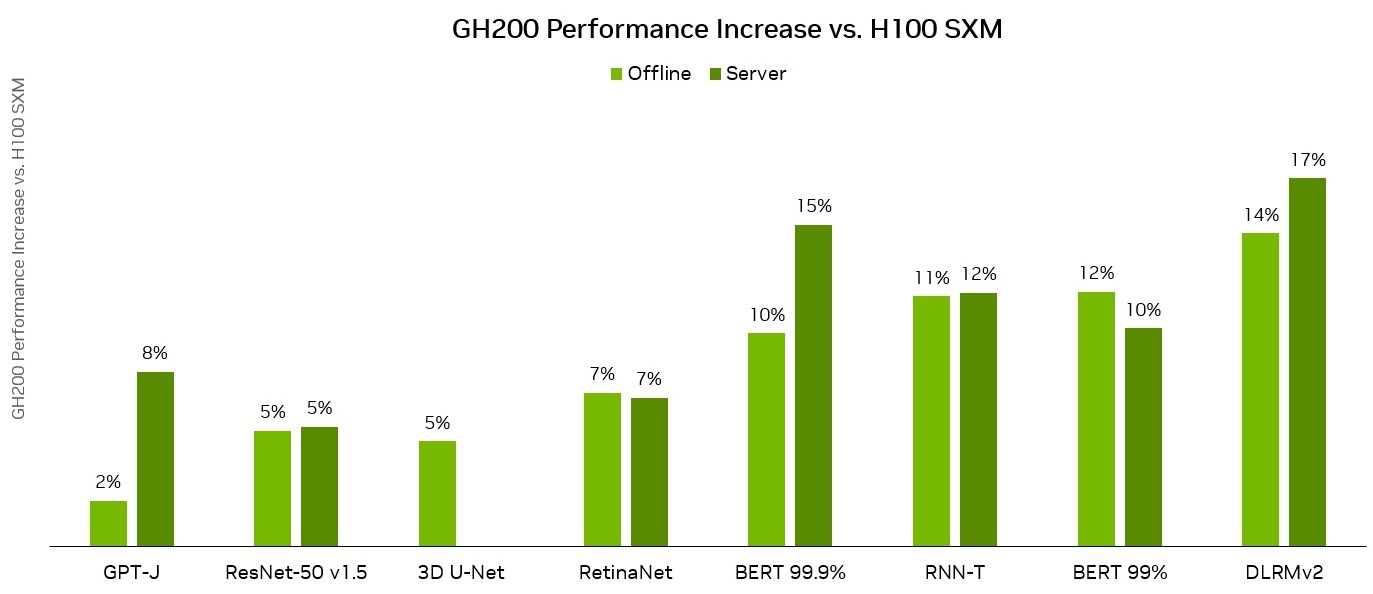
4. Training and Reasoning Scenarios
● Training scenarios: For small to medium-sized model training where GPU computing is the bottleneck, the two products perform similarly; for ultra-large-scale models or training tasks with intensive data preprocessing, the GH200’s memory and collaborative advantages can significantly improve effective throughput.
● Inference scenarios: H100 is better suited for low-latency real-time inference (such as conversational AI and real-time intelligent interaction), with fast token generation rate and flexible deployment; GH200 is suitable for high-load batch inference or ultra-long context inference, with lower long-tail latency and stronger stability.
5. HPC load balancing
● The H100 is suitable for traditional HPC scenarios such as computationally intensive scientific simulation and numerical modeling, and its FP64 computing performance is powerful.
● The GH200 is better suited for complex HPC scenarios such as memory-constrained simulation tasks and large-scale graph computing. The tight coupling between CPU and GPU can break through the scalability limitations of traditional architectures.
V. Typical Adaptation Scenarios
1. Prioritize H100 scenarios.
● The workload is mainly computationally intensive, with no obvious memory or CPU-GPU communication bottlenecks (such as small and medium-sized model training, real-time inference, and traditional HPC simulation).
● In pursuit of cost-effectiveness and versatility, it needs to be compatible with various types of AI and HPC workloads;
● The operations and maintenance team has limited resources and wants to deploy and go live quickly without major modifications to the existing infrastructure;
● Building standard GPU-based AI infrastructure requires compatibility with the existing software ecosystem and deployment processes;
● For most production-grade AI workloads (such as LLM inference and batch data processing), the H100 offers stable performance and flexible adaptability.

2. Prioritize scenarios where GH200 is selected.
● The model is extremely large, and 80GB of memory is insufficient (such as training a model with hundreds of billions of parameters or extremely long contextual inference).
● The load is typically memory-intensive, with a high proportion of data movement time, and memory bandwidth or capacity becomes the performance bottleneck.
● The CPU and GPU work together frequently, and the communication latency of traditional architectures cannot meet efficiency requirements;
● Pursue the ultimate system-level throughput, rather than single-point GPU computing performance;
● Special HPC scenarios that require deep coupling between CPU and GPU, such as scientific simulation and large-scale graph computing.

VI. Practical Recommendations for Product Selection
1. Baseline selection principle: When there is no clear bottleneck in memory or CPU-GPU communication, the H100 should be selected first, as its versatility, cost-effectiveness and ease of operation and maintenance are more suitable for most scenarios;
2. GH200 Applicability Boundaries: Only consider GH200 when a unified memory architecture or tight CPU-GPU integration can bring quantifiable performance improvements, and avoid blindly chasing the latest technology;
3. Testing and verification methods: Conduct end-to-end load benchmark tests, focusing on throughput and latency in actual business scenarios, rather than simply relying on peak floating-point performance (FLOPS).
4. Overall cost considerations: In addition to hardware procurement costs, hidden costs such as power consumption, heat dissipation, and operation and maintenance complexity need to be evaluated simultaneously to avoid an increase in the overall TCO due to excessive adaptation difficulties;
5. Future expansion planning: There is no need to over-optimize for future workload scale unless it is known that the model or data volume will continue to grow and exceed the current hardware limitations.

In summary, choosing computing power is essentially about understanding the workload.
The H100 and GH200 are not replacements, but rather complementary solutions for different load scenarios:
● The H100 is a balanced general-purpose accelerator that performs stably in various scenarios such as training, fine-tuning, and inference. It has high computational density and flexible deployment, making it the preferred solution for most current AI and HPC workloads.
● GH200 is a highly targeted system-level solution that focuses on memory-intensive and CPU-GPU closely coordinated scenarios. It can break through the bottleneck of traditional discrete architectures and provide better performance for special workloads.
In real-world projects, the choice of computing platform often depends on the specific workload characteristics. EMPOWERX has long focused on the selection, testing, and deployment of AI servers and system-level solutions based on mainstream architectures such as H100 and GH200, helping computing power to be deployed in a more suitable form at different stages. If you need to match suitable GPU hardware for your workload or obtain more optimization deployment suggestions, please feel free to contact us.