NVIDIA Rubin Platform Makes a Grand Debut at CES: Six-Core Collaboration Reshapes AI Computing Power, Mass Production Expected in the Second Half of 2026

From an industry evolution perspective, while CES still bears the name of the Consumer Electronics Show, it has now become a crucial platform for tech giants to unveil cutting-edge computing technologies, with its technological reach extending far beyond the consumer market. NVIDIA, as a leader in AI computing power, took the lead by holding a chip manufacturer launch event this year, unveiling its next-generation Rubin AI platform. This clearly reflects this trend and sets the stage for the iteration of AI computing hardware in 2026.
According to NVIDIA, all core chips required for the Rubin platform have completed wafer fabrication and entered the laboratory system debugging phase, with a clear and controllable schedule for mass production and market launch. As a key iteration node in NVIDIA’s computing power roadmap, the core goal of the Rubin GPU and its supporting chips is to achieve breakthroughs in both performance and energy efficiency: single-GPU AI inference performance is 5 times higher than the previous generation Blackwell, and training performance is 3.5 times higher, while supporting upgraded computing, memory, and network resources to build a full-stack computing power support system. This strategy represents NVIDIA’s iterative advancement of its own technology and further consolidates its leading advantage in the field of high-end AI computing power.

Over the past few years, NVIDIA has developed a detailed and transparent technology roadmap for the coordinated evolution of CPU, GPU, and network architectures. For leading computing power vendors, the demand for technological stability and delivery certainty from a large customer base is extremely high, making sudden announcements no longer the optimal choice. Therefore, NVIDIA has shifted to a strategy of “clear expectations and on-time delivery,” synchronizing with ecosystem partners through a clear roadmap to ensure coordinated progress across the industry chain.
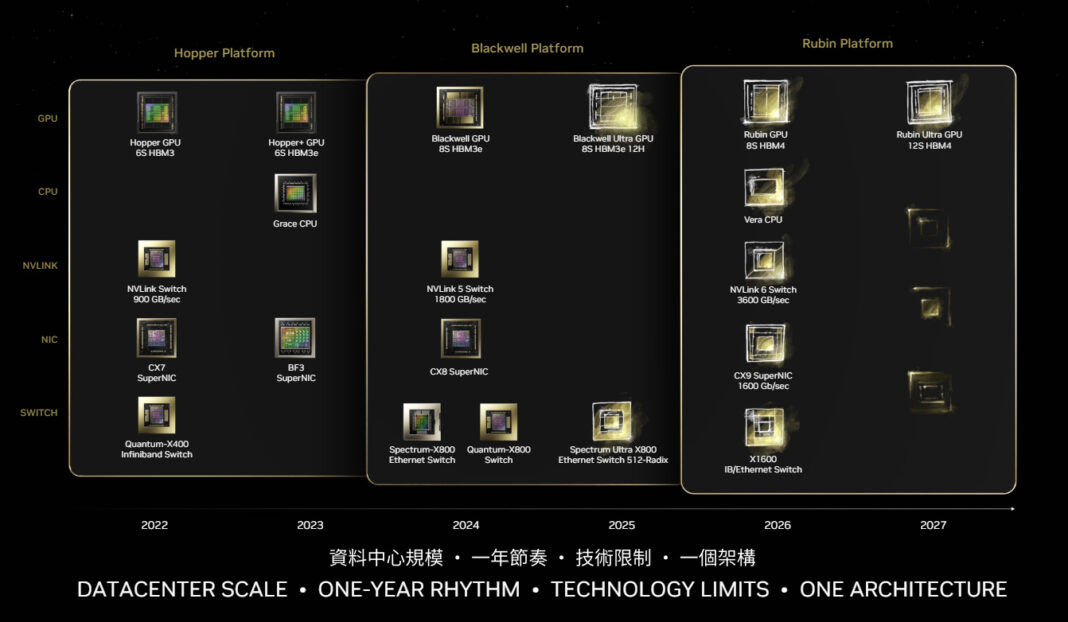
Based on this strategy, NVIDIA’s decision to launch the Rubin platform at CES is essentially a public endorsement of its technological maturity and mass production progress, sending a clear signal that “the entire process is proceeding as planned.” While the hardware has not yet officially shipped, and mass production ramp-up is expected to begin in the second half of 2026, the early release, combined with the already available chip samples and the synchronized adaptation progress of ecosystem partners, is more like a technological warm-up for the industry, reinforcing market expectations for the next-generation computing platform.
It’s important to note that this press conference wasn’t a technical detail-focused event—NVIDIA has already provided supplementary core parameters and architectural details through a separate technical blog post. The conference itself focused on platform-level value output, outlining the core chip composition of Rubin and system adaptation solutions, disclosing only key performance indicators. This layered disclosure approach, combining macro and micro perspectives, aligns with the release practices of leading industry manufacturers while also catering to the information needs of different audiences.
Rubin Platform: Full-Stack Collaboration of CPU + GPU + DPU + Network Interface Card + NVLink + Ethernet Switch
As NVIDIA has been laying the groundwork for over a year, Rubin is both a GPU architecture and a larger, full-stack platform. Although NVIDIA is essentially still a GPU manufacturer, starting with the Blackwell platform, and especially with the Rubin era, the company has tended to market complete systems to customers—and, if conditions permit, even complete SuperPOD clusters. Therefore, the significance of the development and release of the Rubin platform for NVIDIA lies not in launching a high-end chip, but in creating six core chips that work together.

Rubin GPU: The performance core, doubling computing power.
Undoubtedly, the Rubin GPU was the highlight of the entire presentation. As the first product to be implemented using NVIDIA’s next-generation GPU architecture (specific model to be determined), its goal is to surpass the existing Blackwell and Blackwell Ultra (GB200) GPUs in every aspect. NVIDIA is currently keeping the core technical details under wraps, but the key to driving breakthroughs in the AI market is an upgraded Transformer engine that supports compression technology—which NVIDIA calls one of its six “technological wonders.”

Overall, this flagship Rubin GPU, when using the NVIDIA NVFP4 format, can achieve an inference performance of 50 PFLOPS, which is 5 times that of the Blackwell GPU. Although the training performance is slightly less improved, the training performance still reaches 35 PFLOPS under the same format, which is 3.5 times that of Blackwell.

Consistent with its predecessor, the Rubin GPU employs a dual-chip package design, with both chips being “mask-sized” and manufactured using TSMC’s 3nm process. In terms of memory configuration, it features up to 288GB of HBM4 memory, on par with the current Blackwell Ultra. However, compared to the HBM3e memory used in Blackwell, Rubin’s HBM4 memory boasts a bandwidth of 22 TB/s, a surprising 2.8 times improvement over its predecessor.
In terms of transistor count, the Rubin GPU reaches 336 billion, 1.6 times that of Blackwell. However, NVIDIA has not yet disclosed the chip’s power consumption data, only claiming that its performance per watt in inference scenarios is 8 times that of Blackwell, a stark contrast to the 5-fold absolute performance improvement, indicating significant energy efficiency optimization.
NVLink Switch: Doubled bandwidth, full liquid cooling
Rubin GPUs will continue to rely on NVLink technology to interconnect with other GPUs and build larger-scale horizontal scaling clusters. The sixth-generation NVLink (NVLink 6) will double the bandwidth of the fifth generation, with a single GPU NVLink bandwidth of up to 3.6 TB/s. A new generation of NVLink switch chips (the second core chip) will also be launched at the same time.

To support doubled transmission speeds, the NVLink 6 employs 400Gbps SerDes technology. This NVLink 6 switch provides full interconnect bandwidth for each connected GPU, with a peak total bandwidth of 28.8 TB/s. High-density bandwidth transmission generates significant heat, therefore the switch chip must utilize a liquid cooling solution.
Vera CPU: Custom Arm architecture, coordinating full-stack computing power
Vera, NVIDIA’s new high-end Arm architecture CPU (its third core chip), together with the Rubin GPU, forms the core of the “Vera Rubin” naming combination, responsible for coordinating the overall platform’s computational scheduling. It has been confirmed that each Vera CPU features 88 custom Arm v9.2-A architecture cores, codenamed Olympus, supporting NVIDIA’s spatial multithreading technology and enabling 176 threads concurrently. While details of its internal architecture are not yet widely disclosed, NVIDIA has explicitly stated that Vera’s data processing and compression performance are twice that of the Grace CPU.

In terms of memory, the Vera CPU, through the SOCAMM module co-developed with Micron, can accommodate up to 1.5TB of LPDDR5X memory, three times the capacity of the Grace CPU. This modular memory design addresses a major pain point of the Grace-based GB200 platform—the memory is soldered and fixed, making it impossible to replace or upgrade. Overall, the Vera CPU’s memory bandwidth reaches 1.2 TB/s, slightly more than twice that of the Grace CPU.
The standard DGX node will be configured with “1 Vera CPU + 2 Rubin GPUs” and interconnected through the latest generation NVLink-C2C technology, with a bandwidth of up to 1.8 TB/s.
The Vera CPU completes the final piece of the puzzle for NVIDIA’s rack-scale confidential computing. While Blackwell previously supported encrypted workloads, the Grace CPU lacked this capability, limiting confidential computing to the GPU level. The Vera CPU, however, is fully compatible with the confidential computing technology of the Rubin platform, enabling encrypted protection of the entire rack’s computing power.
ConnectX-9 network card and BlueField 4 DPU: Dual support for network and security
The traditional Ethernet connectivity of the Rubin platform is provided by NVIDIA’s new generation ConnectX network cards and BlueField DPU technology. Among them, the ConnectX-9 network card (the fourth core chip) adopts 200G PAM4 SerDes technology, with a network bandwidth of up to 1.6 Tb/s, providing a network foundation for the horizontal scaling of large-scale multi-rack clusters.

Its accompanying BlueField 4 DPU (the fifth core chip) combines the advantages of both new and old technologies, featuring a built-in 64-core Grace CPU and ConnectX-9 network card core. NVIDIA claims that the BlueField 4’s bandwidth, memory bandwidth, and computing performance are 2 times, 3 times, and 6 times that of the previous generation BlueField 3, respectively.

Spectrum-6 Ethernet Switches with Co-packaged Optical Technology: A Leap in Energy Efficiency and Reliability
The final core chip is NVIDIA’s latest Spectrum-6 Ethernet switch, which will serve as the core of the Spectrum-X switch series. It is the first to integrate co-packaged optical technology, significantly reducing power consumption. This switch tightly connects all the hardware on the Rubin platform, forming a complete computing network.

Looking at the Spectrum-6 series separately from the GPU devices, it includes two key Ethernet switch products: the SN6800 and the SN6810. The SN6800 boasts powerful performance, offering 512 800G Ethernet ports or 2048 200G ports, with a total bandwidth of 409.6 Tb/s; the entry-level SN6810 offers 128 800G ports or 512 200G ports, with both the number of ports and the total bandwidth (102.4 Tb/s) being one-quarter of that of the SN6800.

Co-packaged optics technology is the core innovation of this project, which NVIDIA hopes will solve the power consumption and reliability challenges of high-performance, large-scale switches. By sharing a laser source and silicon photonics modulation technology, Spectrum-X switches can achieve high-speed optical network transmission, reduce the number of vulnerable components, and avoid the high power consumption problems of traditional optical networks. NVIDIA has high hopes for this series of switches, claiming that its energy efficiency is 5 times that of comparable traditional switches, and its reliability is 10 times better.
Complete system: Vera Rubin NVL72 and HGX Rubin NVL8
All of the new chips mentioned above will be integrated into multiple NVIDIA systems. Before Rubin is fully commercialized, NVIDIA has confirmed that it will launch two types of systems: an upgraded rack-mount NVL72 system for customers who deeply embrace the NVIDIA ecosystem; and a new generation of 8-way HGX carrier design—HGX Rubin NVL8—for customers who need x86 architecture compatibility.

Consistent with its predecessor, the Grace Blackwell NVL72, a single Vera Rubin NVL72 rack (formerly NVL144) contains 72 Vera Rubin GPUs (144 GPU chips) and 36 Vera CPUs, employing a purely horizontal scaling solution. All GPUs are interconnected via NVLink switches. The entire hardware system boasts a staggering 220 trillion transistors, resulting in considerable power consumption.
In terms of performance, the Vera Rubin NVL72 rack achieves the same level of improvement in key metrics as a single Rubin GPU: a 5x increase in inference performance and a 3.5x increase in training performance, specifically reaching 3.6 EFLOPS (inference) and 2.5 EFLOPS (training). Regarding memory configuration, the LPDDR5X total capacity reaches 54TB (2.5 times that of the GB200 NVL72), the HBM4 total capacity is 20.7TB (1.5 times), and the HBM4 total bandwidth is 1.6PB/s (2.8 times).

In addition to upgrading the core chips, NVIDIA also redesigned the NVL72 rack, addressing many issues present in the Blackwell era. The biggest change is the adoption of a fully cableless modular tray design, significantly reducing rack deployment time—from 100 minutes per rack in the Blackwell era to just 6 minutes in the Rubin era. Simultaneously, the substantial reduction in cable count lowers potential points of failure, further enhancing system reliability.
With the optimization of NVLink technology and the second-generation RAS engine, NVIDIA promises that the Vera Rubin NVL72 rack can achieve zero-downtime operation for health checks and network maintenance.

Supplemental tool: NVIDIA Inference Context Memory Storage Platform
Expanding computing beyond a single NVL72 rack requires the support of NVIDIA’s network technologies. In addition to the ConnectX-9 network cards, BlueField DPUs, and Spectrum-X switches mentioned above, NVIDIA has added a key tool—the inference context memory storage platform, which is essentially a key-value (KV) caching system.

This platform represents another application scenario for NVIDIA network hardware, specifically designed for storing key-value pair data required during inference. Modern large models (especially multi-step models) generate extremely large amounts of context data, which node-level storage struggles to handle. This forces operations personnel to either discard the data and recalculate it later, or deploy additional storage solutions. The KV caching system precisely addresses this pain point, storing context data and enabling rapid retrieval and reuse, avoiding redundant calculations.
Essentially, NVIDIA positions it as a Pod-level optimization technology, aiming to break through the current inference performance bottleneck, claiming to achieve a 5x improvement in inference performance and a 5x improvement in energy efficiency, with significant optimization effects.

At the hardware level, the platform is built on NVIDIA network products, not off-the-shelf devices like DGX or Spectrum-X. NVIDIA provides the core components, and partners complete the subsequent assembly. It uses SSD storage and BlueField/ConnectX hardware to build context memory storage nodes, which are then interconnected with AI nodes.
Although not a directly developed product of NVIDIA, the company has invested heavily in this technology: not only developing supporting network hardware, but also adding related software features to the CUDA ecosystem and adapting it to frameworks such as Dynamo and DOCA. NVIDIA itself will also adopt this technology in its top-of-the-line SuperPOD system.
DGX SuperPOD: The Ultimate Computing Cluster in the Rubin Era
Leveraging the new GPU architecture and NVL72 racks, NVIDIA has completed the Rubin hardware ecosystem with its SuperPOD clusters. Consistent with the Blackwell era, SuperPOD serves as both a blueprint and validation solution for large-scale GPU clusters, and a commercial product that NVIDIA sells to its customers.
NVIDIA offers customers two types of Rubin SuperPOD configurations: one is based on the Vera Rubin NVL72 rack, integrating eight of these racks, Spectrum-X Ethernet switches, Quantum-X800 InfiniBand switches, BlueField 4 DPUs, and context memory storage nodes, representing the highest performance level of the Rubin platform.

In terms of parameters, a DGX SuperPOD based on Vera Rubin NVL72 includes 8 NVL72 racks, with a total of 576 GPUs, 288 CPUs and about 600TB of memory. The total computing power reaches 28.8 EFLOPS at NVFP4 precision, and the NVLink bandwidth is sufficient to support the models in the rack to run without partitioning.
Another type is aimed at x86 users, which builds SuperPOD based on DGX Rubin NVL8 nodes. The density is relatively low – 64 NVL8 nodes make up a SuperPOD, providing 512 GPUs. The overall design adopts a similar horizontal expansion design, and the core relies on NVIDIA hardware to achieve cross-rack expansion.
Rubin platform: Officially launched in the second half of 2026.
NVIDIA is currently in the hardware debugging phase for Rubin, but its ecosystem partners are working hard to prepare supporting services and compete for the first batch of Rubin service deployments. NVIDIA revealed that major public cloud providers such as AWS, Google Cloud, Microsoft, and OCI will be among the first cloud service providers to deploy Vera Rubin instances in 2026.
Ultimately, NVIDIA plans to deliver mass-produced hardware to its partners in the second half of 2026, helping them to launch related products and services simultaneously. The DGX series of complete systems will also be available at the same time.
Fuchuang [Shenzhen Haoyuan Nuoxin] has always focused on cutting-edge technologies and product iterations in the field of AI computing power, and has been deeply involved in the construction of AI computing power infrastructure to help customers accelerate the implementation and large-scale deployment of various AI applications.
