DeepSeek Large Model Inference Solution for University Research
As AI technologies continue to advance, university research teams are increasingly moving beyond theoretical model development toward real-world deployment and validation.
For projects centered on large language models (LLMs), especially generative AI, the challenge is no longer limited to model training. Instead, it has shifted to a practical question:
How can large models be deployed efficiently, stably, and repeatedly in real research environments?
Model scale, resource constraints, environment reproducibility, and multi-task experimentation often become bottlenecks during the validation stage. To address these challenges, a flexible and high-performance inference platform is required.
This case highlights how a university AI research group deployed an integrated large-model inference platform built on 5th Gen Intel® Xeon® Scalable processors and multi-GPU architecture to support DeepSeek-based research workloads.

Project Background: From Training to Deployment Validation
The research team focuses on generative AI applications in educational text generation, reading comprehension, and language understanding. Their primary research models are based on the open-source DeepSeek series, with multiple rounds of fine-tuning already completed.
However, as the project transitioned from model development to deployment validation, several infrastructure challenges emerged:
- Large model sizes leading to high memory and compute demand
- Frequent server instability during intensive inference testing
- Parallel multi-model experimentation increasing debugging overhead
- Repeated environment reconfiguration impacting research efficiency
It became clear that a stable, high-throughput, and flexible inference platform was essential for the next stage of research validation.
Experimental Focus: Multi-Task and Multi-Model Validation
The experimental framework centered on DeepSeek models, with emphasis on three categories of generative evaluation:
1、Multi-Variable Prediction
Assessing whether the model maintains consistent reasoning under multiple semantic variables.
2、Long-Context Understanding
Testing the model’s ability to process extended input sequences while preserving contextual coherence.
3、Conditional Generation
Evaluating instruction-based or label-controlled text generation accuracy and stability.
These evaluation tasks not only tested model capability but also placed significant demands on:
- Inference throughput
- Resource scheduling flexibility
- Rapid environment switching
- Concurrent multi-model execution
Deployment Architecture: Integrated AI Inference Platform
To support these requirements, a customized inference solution was deployed based on a dual-socket architecture powered by 5th Gen Intel® Xeon® processors, combined with multi-GPU acceleration.
Hardware Architecture
- Dual-socket server platform
- Support for up to eight high-performance GPUs
- High-speed DDR5 memory
- PCIe 5.0 high-bandwidth interconnect
- Optimized internal topology for multi-threaded and multi-model workloads

This configuration ensures stable support for intensive inference tasks and concurrent experimental workflows.
Software and Environment Integration
The platform includes a pre-integrated AI inference environment featuring:
- DeepSpeed and vLLM inference frameworks
- Rapid multi-model version switching
- One-click deployment and environment reuse
- Task scheduling scripts
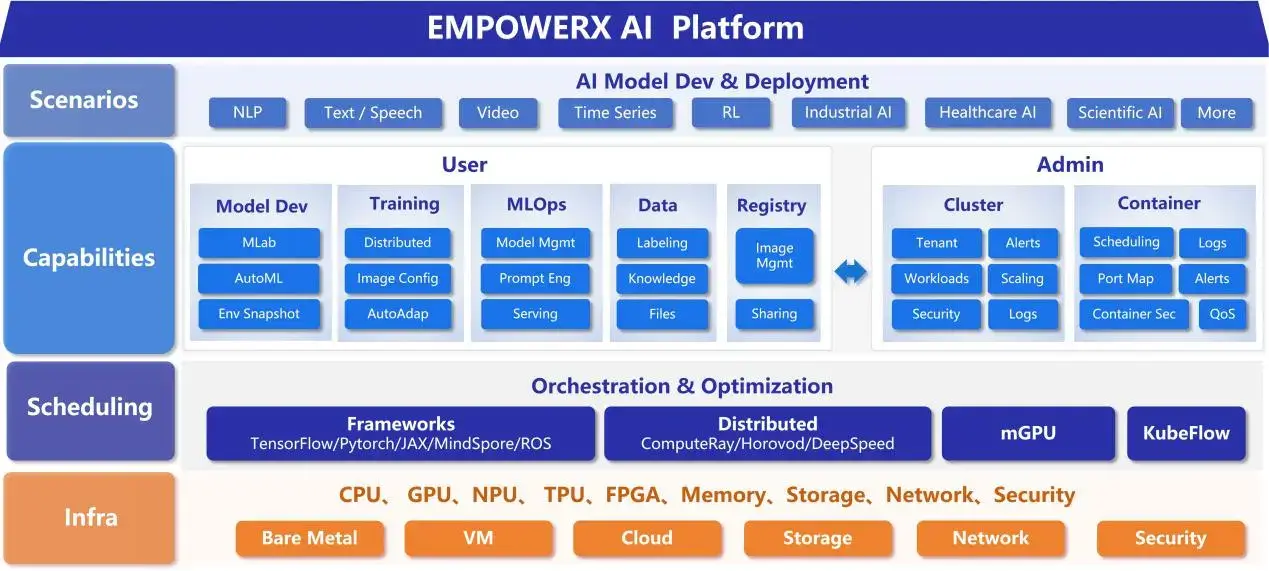
Beyond Hardware: A Research-Ready AI Inference Platform
This solution extends beyond raw compute hardware. It provides a complete, integrated AI inference platform designed to support ongoing research evolution:
- Pre-configured hardware with factory-level performance tuning
- Pre-installed inference frameworks and runtime environments
- Common task templates and scheduling scripts
- Customized technical support and remote assistance
By minimizing time spent on environment setup, dependency configuration, and system tuning, researchers can focus directly on model optimization and experimental innovation.

Conclusion: Building the Infrastructure Foundation for Applied AI Research
As AI research increasingly transitions toward practical deployment and application validation, infrastructure capability becomes a decisive factor in research productivity.
EmpowerX provide integrated AI server and deployment solutions tailored for universities, research institutes, and innovation-driven laboratories, including:
- Pre-integrated training and inference platforms
- Scalable multi-GPU system architectures
- Deployment optimization aligned with real-world research workloads
- Responsive technical collaboration and remote support
A robust inference foundation enables academic institutions to accelerate experimentation cycles and bridge the gap between theoretical research and applied AI systems.